
I Made Claude Prove its hallucination
I stopped using 1 clever model and built a local multi-agent debugging workflow that had to earn every answer before I trusted it.

I built this because 1 model kept doing what smart systems do when nobody checks them
it sounded right before it was right
it would explain a write conflict like a deploy issue
it would invent a field never in the schema
it would smooth over replica lag like a tiny retry bug
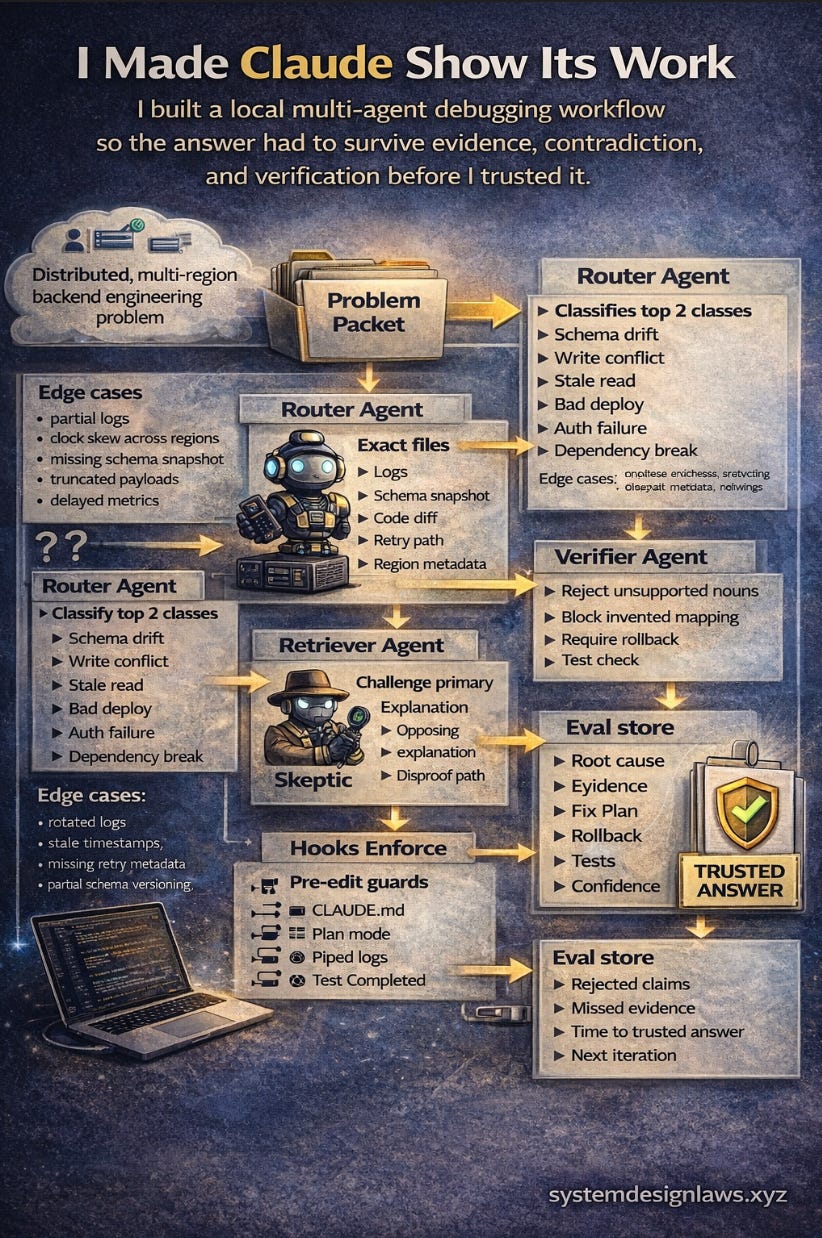
So I built a local debugging copilot for backend failures
input → incident summary, logs, schema snapshot, deploy diff, region metadata, retry paths
workflow → router classifies → retriever pulls evidence → skeptic attacks theory → verifier blocks unsupported claims
output → root cause, evidence, fix plan, rollback, tests, confidence

Table of contents
1. Why I Built It - The workflow problem behind confident model fiction
2. The Product – Local debugging copilot for backend failures
3. What I Built – Router, Retriever, Skeptic, Verifier workflow
4. The Shapes That Matter – Session vs subagents vs teams
5. The Agent Roles – Narrow workers that force evidence
6. The Debugging Loop – Break agents, tighten roles, replay incidents
7. How I Ran It
Install
Configure
Launch
Debug
Tighten
8. Where It Worked
Schema changes
Cross-region write conflicts
Deploy vs replica lag confusion
9. What The Current Docs Changed For Me
10. What I Would Change Next
11. FAQ
12. Summary
Why I built it
The problem was simple: 1 model read partial evidence, locked onto the first neat explanation and returned confident fiction. This was not a model intelligence problem, it was a workflow problem. I let 1 system retrieve evidence, reason about it, challenge itself and verify itself in the same breath. That is how clean nonsense slips into real engineering decisions.
The product
I turned that frustration into a local debugging copilot for common backend failures. Input included incident summary, logs, schema snapshot, code diff, region metadata and retry paths. Output produced likely root cause, exact evidence, safe fix plan, rollback path, tests and confidence. It was not a chatbot. It was a local evidence engine for failures that waste the most engineering time. Example: a write lands in 1 region, a retry fires in another, the dashboard reads a lagging replica and support sees mismatched state. Without structure the model blames the deploy. With structure the system checks idempotency, write order, read source and replica lag before it is allowed to speak.
What I built
I kept the system local because that is where bad answers surface faster. Local loops give cheaper iteration, tighter control and less theater. I used Claude Code as the shell layer because it supports terminal install, CLAUDE.md project memory, subagents, hooks, CLI prompts and experimental agent teams. In practice the terminal flow remained the cleanest way to control the entire workflow from 1 place. The system itself is a Claude workflow where narrow workers split the debugging task, forcing every answer to pass evidence, contradiction and verification. Without it the model picks the first tidy story. With it the answer has to earn its way into the room. Multi-agent does not make the system smarter by default; it works only when each worker has a narrow job and 1 worker can say no.
The shapes that matter
The workflow works best when thinking in 3 layers instead of 1. A single session works for small bugs, narrow file sets and quick fixes, but breaks when retrieval, contradiction and verification mix together. Subagents work well for focused tasks where only the result matters or for search-heavy investigation, and Claude Code provides built-in workers like Explore and Plan plus custom subagents in .claude/agents/. Agent teams work better when competing hypotheses, research or cross-layer coordination are required, though they remain experimental and heavier to coordinate. The practical rule became simple: use subagents when only the result matters and teams when workers must challenge each other.
The agent roles
The system split debugging into 4 jobs. The router classifies the failure first such as schema drift, write conflict, stale read, bad deploy or auth failure. The retriever pulls exact logs, fields, timestamps, files and configuration. The skeptic attacks the first explanation and forces a different root-cause family. The verifier rejects any answer mentioning tables, regions, fields or APIs that never appeared in the evidence. The goal was not parallel agents doing the same work; the gain comes from strict role separation.
The debugging loop
The real project was not building agents; it was debugging the agents while they debugged incidents. The loop was simple: let the system fail, identify which role failed, tighten that role, replay the same incident and keep the change only if the answer became more grounded instead of more eloquent. The first failures revealed the weak points quickly. The router blamed every issue on deploys, so I forced it to produce 2 competing failure classes before any explanation. The retriever returned too much noise, so I restricted it to exact evidence only. The skeptic sounded clever but repeated the first theory, so I required it to produce a materially different explanation. This was not prompt tweaking. It was workflow debugging.
How I ran it
Install
I would recommend macOS setup in this order so nothing stupid steals 30 minutes.
Claude Code’s docs currently recommend the native install on macOS, Linux, and WSL and they also support a Homebrew cask install. Native installs auto-update. (Claude)
Check the machine first.
# install Claude Code CLI
curl -fsSL https://claude.ai/install.sh | bash
# add Claude to PATH
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.zshrc
# reload shell
source ~/.zshrc
# launch Claude CLI
claude
# macOS version
sw_vers
# CPU architecture
uname -m
# active shell
echo $SHELLInstall GitHub CLI.
# ensure Homebrew exists (required for gh install)
command -v brew || /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# fix brew path on Apple Silicon
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)"
# update package index
brew update
# install GitHub CLI
arch -arm64 brew install gh
# verify installation
gh --version
# authenticate with GitHub
gh auth login
# confirm login
gh auth statusInstall Apple Command Line Tools if they are missing.
# install Apple developer tools if missing
xcode-select -p || xcode-select --install
# verify git
git --version || true
# verify compiler
clang --version || trueInstall Homebrew if it is missing.
# fix Homebrew path for Apple Silicon
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zprofile
# activate brew environment
eval "$(/opt/homebrew/bin/brew shellenv)"
# check PATH
echo $PATH
# confirm brew location
which brewInstall the supporting tools I actually wanted around Claude.
# update brew packages
brew update
# check brew environment health
brew doctor
# install useful CLI tools
brew install jq tmux node git
# verify jq
jq --version
# verify tmux
tmux -V
# verify node
node -v
# verify git
git --versionConfigure
Current docs recommend generating a starter
CLAUDE.mdwith/init, then refining it over time. They also stress keepingCLAUDE.mdconcise because it is loaded every session as context, not as an enforcement file. (Claude)Create the repo and folders.
mkdir -p ~/src
cd ~/src
mkdir claude-debug-copilot
cd claude-debug-copilot
mkdir -p src logs data scripts .claude/agents .claude/hooks
printf "ANTHROPIC_API_KEY=replace_me\n" > .env
touch CLAUDE.md
ls -la
tree -a . 2>/dev/null || find . -maxdepth 3 -printStart Claude and let it create the first memory file.
claude
/initThen I rewrote
CLAUDE.mdwith the rules that mattered.
cat > CLAUDE.md <<'EOF'
Project goal
- Diagnose recurring backend failures using evidence first
Output contract
- root cause
- evidence
- fix plan
- rollback
- tests
- confidence
Rules
- never invent fields, tables, APIs, regions, or files
- retrieve before explaining
- verifier blocks unsupported nouns
- skeptic must produce a materially different theory
- no edits until the plan is approved
EOF
Enable agent teams because the docs say they are experimental and disabled by default behind (Claude)
mkdir -p ~/.claude
cat > ~/.claude/settings.json <<'EOF'
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}
EOF
cat ~/.claude/settings.json
Add custom subagents because current docs support custom definitions in
.claude/agents/, plus built-ins like Explore and Plan. (Claude)
cat > .claude/agents/router.md <<'EOF'
---
name: router
description: Classify engineering failures before analysis starts
tools: Read,Grep,Glob
---
Classify the issue as schema drift, write conflict, stale read, bad deploy, auth failure, or dependency break.
Return only the top 2 likely classes and what evidence is missing.
EOF
cat > .claude/agents/retriever.md <<'EOF'
---
name: retriever
description: Pull exact evidence and avoid broad guessing
tools: Read,Grep,Glob,Bash
---
Find exact file names, log lines, payload fields, schema definitions, retry paths, timestamps, and region metadata relevant to the issue.
Do not explain root cause.
EOF
cat > .claude/agents/skeptic.md <<'EOF'
---
name: skeptic
description: Attack the first explanation
tools: Read,Grep,Glob
---
Given a proposed cause, produce a competing explanation from a different failure family and list contradictions.
EOF
cat > .claude/agents/verifier.md <<'EOF'
---
name: verifier
description: Reject unsupported claims
tools: Read,Grep,Glob
---
Reject any answer that mentions fields, APIs, regions, or files not present in retrieved evidence.
Require fix plan, rollback, tests, and confidence.
EOF
Add a hook because the docs position hooks as deterministic controls at lifecycle events, and the hook guide explicitly walks through
/hookson macOS withosascriptnotifications. The hooks reference and changelog also call outTeammateIdleandTaskCompletedas events you can use to stop weak work from getting marked done. (Claude)
cat > .claude/hooks/check-edits.sh <<'EOF'
#!/usr/bin/env bash
set -euo pipefail
input="$(cat)"
file="$(echo "$input" | jq -r '.tool_input.file_path // empty')"
if [[ "$file" == *.env || "$file" == *package-lock.json || "$file" == *pnpm-lock.yaml ]]; then
echo "Blocked protected file: $file" >&2
exit 2
fi
exit 0
EOF
chmod +x .claude/hooks/check-edits.sh
Optional macOS notification hook from the docs.
osascript -e 'display notification "Claude Code needs your attention" with title "Claude Code"'
Launch
Claude Code can start directly in a project with
claude, and the docs also show plan mode withclaude --permission-mode planfor safe read-only analysis before edits. (Claude)
cd ~/src/claude-debug-copilot
claude --permission-mode plan
Press "Shift" + "Tab"
Enter - "scan this repo and explain the debugging architecture"
Use Ctrl + C - 2-times to exit claude terminal
My first working prompt inside Claude was this.
Create a small team for debugging recurring backend failures.
Use 4 roles:
1. router
2. retriever
3. skeptic
4. verifier
Flow:
- router classifies the failure first
- retriever pulls exact evidence only
- skeptic attacks the first theory with a different failure family
- verifier blocks unsupported claims
Rules:
- no edits until the plan is approved
- every noun in the answer must appear in retrieved evidence
- final output must contain root cause, evidence, fix plan, rollback, tests, and confidence
Debug
The docs show Claude Code working well with pipes and headless CLI prompts, including
tail -f app.log | claude -p ...andgit diff main --name-only | claude -p .... That was perfect for my debugging loop because I wanted live evidence flowing into the system instead of me retyping symptoms like a tired witness. (Claude)Feed the system a real incident pack.
mkdir -p logs incidents data
touch incidents/incident-001.txt
touch logs/app.log
touch data/schema.sql
git diff main > data/deploy.diff
brew install tree
tree -L 2
echo "2026-03-06T14:22:31Z ERROR write conflict on users id=441 region=us-east-1 replica_lag=240ms" >> logs/app.log
echo "2026-03-06T14:22:32Z WARN retry attempt=1 service=api-gateway region=us-west-2" >> logs/app.log
echo "2026-03-06T14:22:34Z ERROR schema mismatch column=user_email expected=email" >> logs/app.log
cat logs/app.log
Run read-only analysis first.
claude --permission-mode plan
Enter in claude prompt "analyze incident-001 using router retriever skeptic verifier agents"
Stream logs into Claude.
In another terminal feed logs into it:
tail -n 20 logs/app.log | claude -p "Flag signals of stale reads, write conflicts, schema drift, or retry duplication. Return only evidence and next checks."
-----
echo "2026-03-06T15:02:09Z INFO write start id=441 region=us-east-1" >> logs/app.log
echo "2026-03-06T15:02:10Z ERROR retry duplicate write id=441 region=us-east-1" >> logs/app.log
echo "2026-03-06T15:02:11Z WARN replica lag detected region=us-east-1 lag=280ms" >> logs/app.log
tail -n 20 logs/app.log | claude -p "Flag signals of stale reads, write conflicts, schema drift, or retry duplication. Return only evidence and next checks."
Expected Output:
Read the logs and produced a diagnosis hypothesis based on the evidence you fed it.
It analyzed the last log lines and concluded this likely sequence:
1. A write started for id=441 at 15:02:09
2. The system read from a lagging replica (~280 ms behind)
3. The replica did not see the write yet → looked like the record did not exist
4. The retry logic fired
5. Two retries attempted the same write → duplicate write errors
So the likely root issue is:
replica lag + retry logic without idempotency protection
Meaning the system retried a write that had already succeeded.Review changed files are in deploy?
git diff main --name-only | claude -p "Review these changed files for schema drift, unsafe writes, missing idempotency checks, and rollback risk."
Expected Output:
Some of its claims are speculative, because:
- your repo is tiny
- there is no real service code
- the schema file is a toy
- deploy.diff is empty
# Generate logs
echo "2026-03-06T15:02:12Z ERROR retry duplicate write id=442 region=us-east-1" >> logs/app.log
# Waits for new log lines. If nothing arrives, nothing prints.
tail -f logs/app.log | claude -p "..."Search the repo for likely conflict points.
grep -RniE "idempotency|retry|replica|readPreference|upsert|version" .
Pipe those logs back to Claude(Now has multiple events, not one lonely log line pretending to be a system):
tail -n 20 logs/app.log | claude -p "Detect retry loops, replica lag windows and idempotency failures. Return only root cause candidates."
Output:
“Retries are hitting a stale replica so idempotency fails and we fire concurrent duplicate writes.”Forces Claude to challenge its own diagnosis by producing a main theory and a rival theory, then listing what evidence is missing or contradictory.
claude -p "Given the evidence gathered so far, produce 1 primary theory and 1 competing theory from a different failure family. Include only contradictions and missing proof."
expected outcome - Most likely cause is retry loop hitting a lagging replica, but it cannot be proven because deploy changes and successful write logs are missing.Tighten
Once the interactive loop worked, I pushed the strict verifier into API mode. Claude Code’s docs also note model aliases and full model names in model config, so I kept the runner simple and let the environment decide the exact model string when needed. (Claude)
npm init -y
npm i @anthropic-ai/sdk dotenv
cat > src/run.js <<'EOF'
import 'dotenv/config'
import Anthropic from '@anthropic-ai/sdk'
const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY })
const result = await client.messages.create({
model: 'sonnet',
max_tokens: 1200,
messages: [
{
role: 'user',
content: `
You are the verifier.
Reject unsupported claims.
Return strict JSON with:
- verdict
- missing_evidence
- unsafe_claims
- next_step
`
}
]
})
console.log(JSON.stringify(result, null, 2))
EOF
node src/run.js
Expected outcome: the verifier script calls the Anthropic API and prints structured JSON with the incident verdict.
I also kept a reusable command set for replays.
claude -p "Summarize the incident using evidence only"
claude -p "Find unsupported nouns in the current diagnosis"
claude -p "Write a rollback plan with explicit tests"
claude -p "List what evidence would disprove the primary theory"
Where it worked
Before payload mismatch → partial writes; after workflow blocked fake mappings.
New field arrived → old transform ran → partial writes began → model invented mapping.
Workflow: Router flagged contract drift → Retriever pulled payload + schema → Verifier blocked answers until mapping was explicit.
Not “schema drift = migration problem”; often a boundary problem first.
Before replica lag looked like a deploy issue; after evidence forced the right answer.
Write in one region → retry in another → dashboard read lagging replica → humans blamed deploy.
Workflow: Retriever pulled timestamps + region headers + lag signals → Verifier required one story matching evidence.
Not “cross-region bugs need more logs”; they need the right logs in order.
Before timing looked like causality; workflow broke that illusion.
Deploy near incident → proximity looked like proof.
Fix: force top 2 causes, force contradiction, force evidence nouns.
Stopped letting proximity masquerade as proof.
What the current docs changed for me
Cleaner ladder from experiment → workflow: native install, CLAUDE.md memory, subagents, teams (experimental), hooks, plan mode, CLI replay.
What I would change next
Split Verifier → noun checker + action checker; log rejected claims to expose hallucination patterns.
Create eval packs for schema mismatch, stale read, retry duplication, auth drift, rollback failure.
Use teams only when coordination is real; otherwise use cheaper subagents.
FAQ
Why not just use 1 bigger model?
One model searches, guesses and defends itself; splitting roles forces checks. Example: the verifier stopped the diagnosis because deploy.diff was missing. Use it to slow bad conclusions, not to chase speed.
Did multi-agent remove hallucination?
No, it only reduced cheap guesses by forcing evidence checks. Example: the system kept returning “missing proof” when logs and schema were incomplete. Treat outputs as hypotheses that must earn evidence.
When should I use subagents vs teams?
Use subagents for narrow tasks and teams when workers must challenge each other. Example: retriever surfaced log lines while verifier rejected unsupported retry claims. Start small so the signal stays clear.
What would a senior engineer assume?
“Nice debugging helper.” Example: grep and claude -p quickly surfaced retry and replica lag signals. The excitement is speed, the caution is still reading the logs yourself.
What would a staff engineer assume?
“This is an evidence pipeline.” Example: logs → grep → Claude → hypothesis. Keep the pipeline honest by feeding real artifacts, not summaries.
What would a principal engineer assume?
“This is a safety layer before action.” Example: verifier demanded the deploy diff before accepting any root cause. Use it to block risky fixes until proof shows up.
What would a distinguished engineer assume?
“The value is controlling incomplete evidence.” Example: the system refused to confirm the replica-lag theory without write-success logs. The excitement is trust under pressure.
What would a non-technical stakeholder care about?
Faster trusted diagnosis. Example: one command summarized duplicate write failures from logs. The caution is framing it as guidance, not an automatic decision maker.
What breaks first at larger scale?
Missing or stale evidence. Example: an empty deploy.diff blocked both root-cause theories. Keep artifacts flowing or the system goes blind.
What is the cheapest useful version?
1 repo, logs, CLI loop and verifier. Example: tail logs/app.log | claude -p already produced root-cause candidates. Start there and let the excitement come from watching evidence turn into insight.
Summary
I built this because 1 model kept sounding right before it was actually right.
So I split the work into router, retriever, skeptic and verifier and forced every answer to survive evidence, contradiction and proof.
I ran it locally first because local loops expose weak reasoning faster and cheaper. Example: the system stopped the diagnosis when
deploy.diffwas empty.The real project was not just the debugging assistant. It was debugging the assistant while it debugged the incident. Example: logs showed retry duplicates but the verifier refused to confirm the cause without write-success evidence.
Current Claude Code docs helped because they now show a clear ladder from local experiment to repeatable workflow.
Ref - https://github.com/jimmymalhan/claude-debug-copilot