
Unlocking 99.999 % Availability with Global NoSQL - Are You Really Ready?
If you say “I want zero downtime,” fine - but are you ready to design like Amazon, spend like Google, and think like Meta?

TLDR
• 99.999 percent availability equals less than 5 minutes downtime per year.
• Single-region setups cannot cross that line. Global replication is mandatory.
• Each extra 9 costs 10 times more money, time, and talent.
• You trade simplicity for survivability and speed for certainty.
• The moment you automate globally, your smallest mistake travels worldwide.
• Five 9s is not tech. It is temperament.
How it works?
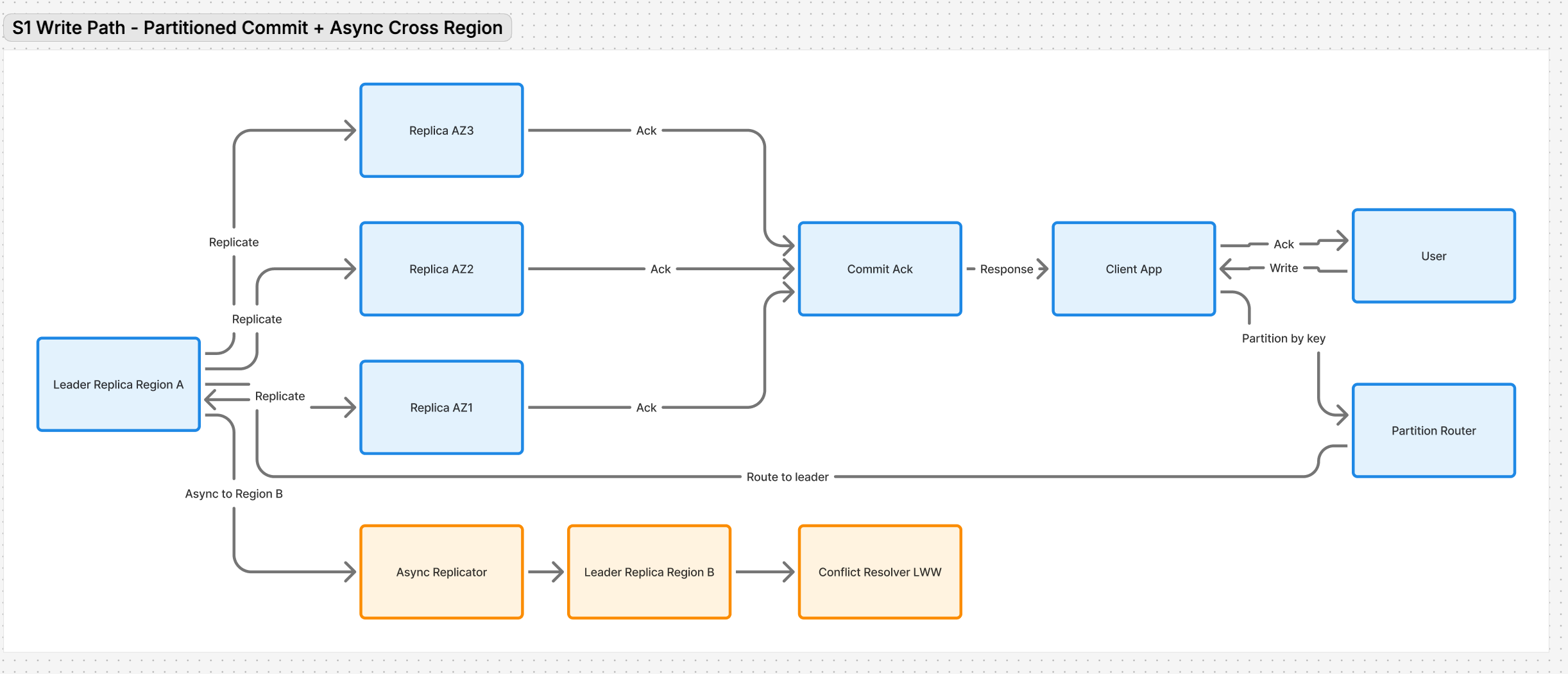
S1 – User sends a write request. Dynamo-like systems split the request by partition key, route it to a local leader replica, and commit to 3 Availability Zones in 1 Region. That is the baseline. Problem – Regional loss wipes all zones together. Solution – Add asynchronous replication to a second Region. Risk – cross-region latency adds 0.5–1 second, conflicts appear. Trade off – “last writer wins” sacrifices consistency for uptime.
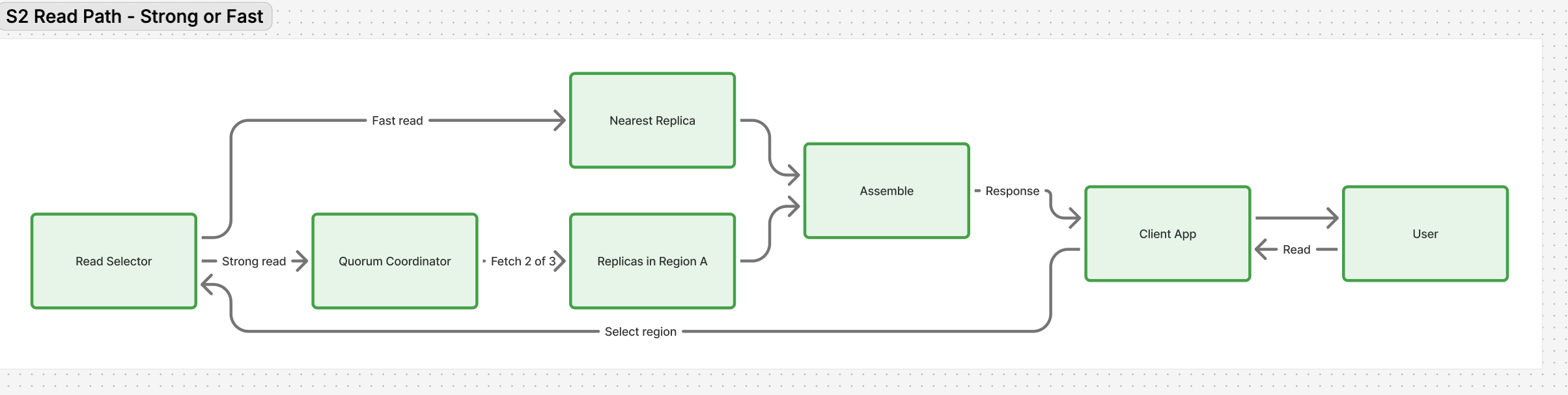
S2 – User performs read. Naive design: always read from primary Region. Problem – users in Asia hitting US Region face 200 ms delay. Overkill design: read from any replica globally. Trade off – may serve stale data, but latency drops 5×. Algorithmic fix – use quorum reads (2 of 3 replicas must agree) for strong reads where needed.
S3 – Global replication. Problem – simultaneous writes in different Regions
